Zeitkomplexität (Time Complexity)
Datum: April 2025
Lesedauer: 8 Minuten
“Unter der Zeitkomplexität wird in der Informatik die Anzahl der Rechenschritte verstanden, die ein optimaler Algorithmus, in Abhängigkeit von der Länge der Eingabe, zur Lösung benötigt.”
Quelle: Wikipedia
Die Big O-Notation stellt diese Komplexität dar und hilft somit bei der Analyse und dem Vergleich des Ressourcenverbrauchs verschiedener Algorithmen. Dies ermöglicht die Implementierung performanter und skalierbarer Systeme.
Aufbau der Formel
Die Effizienz wird wie folgt beschrieben.
Beispiel: O(2^n)
n: Datenmenge
O: Ordnung des Wachstums - wie langsam der Algorithmus mit wachsendem n wird
In diesem Beispiel wird die benötigte Ausführungszeit mit wachsender Datenmenge exponentiell erhöht.
Das Resultat ist unabhängig vom Rechner. Es geht lediglich um die Anzahl benötigter Schritte der Ausführung.
Zudem spiegelt die Notation meist keine exakten Zählung wider, sondern beschreibt das grobe Verhältnis.
Übersicht
Die folgenden Komplexitätstypen werden nachfolgend beschrieben.
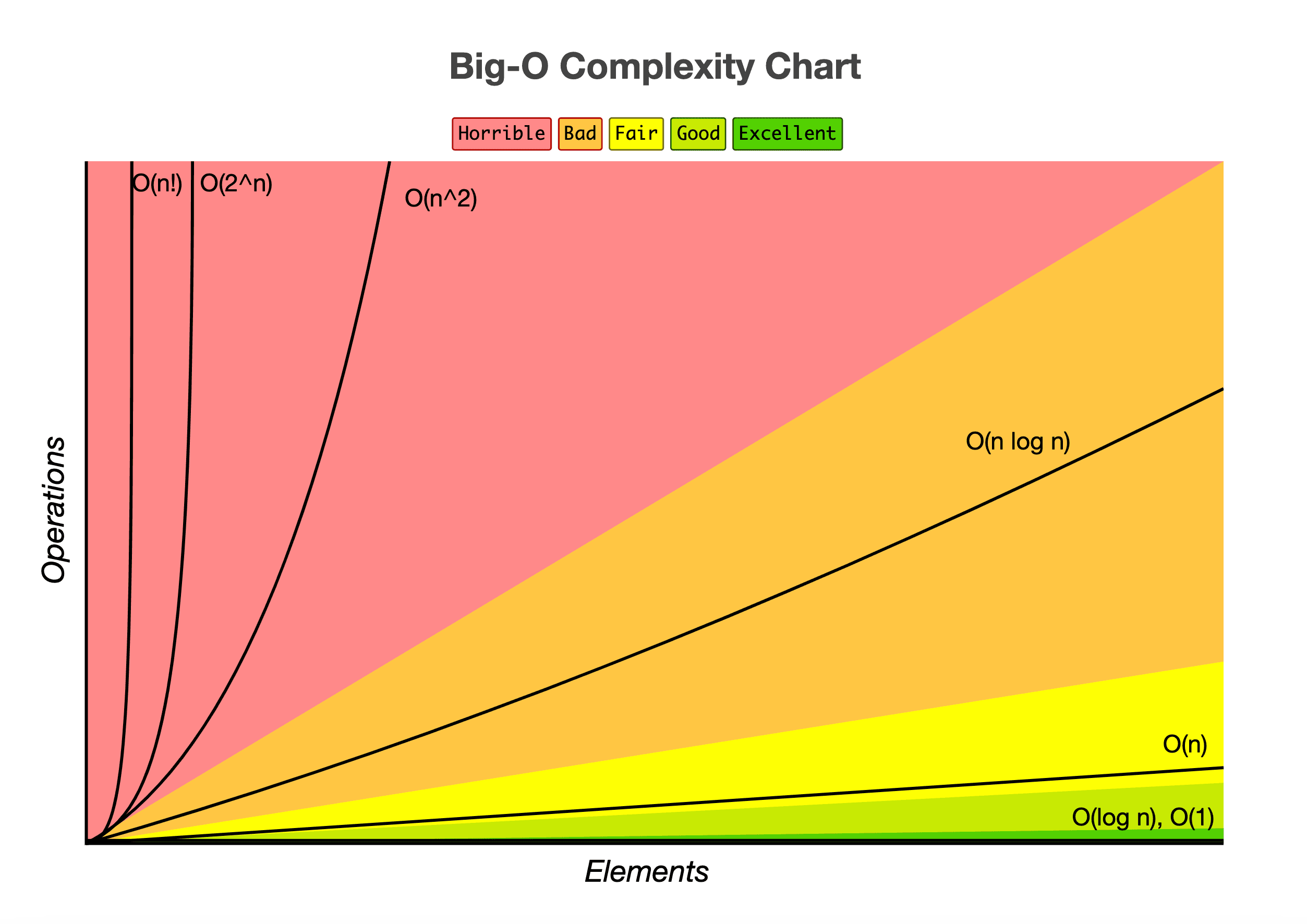
Quelle: https://www.bigocheatsheet.com/
| Notation | Bezeichnung | Beispiel |
|---|---|---|
| O(1) | Konstant | Zugriff auf ein Array-Element |
| O(log n) | Logarithmisch | Binäre Suche |
| O(n) | Linear | Durchlauf eines Arrays |
| O(n log n) | Log-linear | Mergesort, Heapsort |
| O(n^2) | Quadratisch | Doppelte Schleife, z. B. Bubble Sort |
| O(2^n) | Exponentiell | Rekursive Lösungen, z. B. Fibonacci-Folge |
| O(n!) | Faktoriell | Brute-Force bei Permutationen |
O(1) | Konstant
Diese Komplexitätsklasse benötigt, unabhängig der Datenmenge, die gleiche Anzahl an Schritten und ist damit theoretisch optimal.
In der Praxis kann z. B. eine logarithmische Lösung die Konstante Kompexität übertreffen. Zudem garantiert O(1) nicht eine einzelne Operation. Es bedeutet, dass der Aufwand unabhängig von der Eingabegrösse ist. Dieser Aufwand kann jedoch auch zehn konstante Schritte umfassen.
function getFirstElement(arr) {
return arr[0];
}Auch wenn der Array tausend Einträge hat, ist lediglich eine Operation notwendig.
O(log n) | Logarithmisch
Bei der logarithmischen Komplexität wächst die Ausführungszeit mit zunehmender Datenmenge nur langsam, da die Anzahl der zu prüfenden Elemente bei jedem Schritt halbiert wird.
Ein Beispiel hierfür ist die Binäre Suche, bei welcher der zu durchsuchende Bereich einer Liste stetig halbiert wird.
Hat die Liste vier Einträge, sind zwei Halbierungen nötig: log(4) = 2
Für acht Elemente bereits drei: log(8) = 3
Aber auch wenn die Liste stark wächst, so folgen die Schritte nur langsam: log2(1024) = 10
function binarySearch(arr, target) {
let left = 0;
let right = arr.length - 1;
while (left <= right) {
const middle = Math.floor((left + right) / 2);
if (arr[middle] === target) {
return middle;
} else if (arr[middle] < target) {
left = middle + 1;
} else {
right = middle - 1;
}
}
return -1;
}Nur zehn Schritte sind nötig, um eine Liste mit tausend Einträgen zu durchsuchen.
O(n) | Linear
Die Zeit erhöht sich proportional zur Datenmenge.
function hasItem(arr, target) {
for (let item of arr) {
if (item === target) {
return true;
}
}
return false;
}Für einen Array mit tausend Einträgen sind hierfür ca. tausend Schritte nötig.
O(n log n) | Log-linear
Die Ausführungszeit gleicht zunächst der der linearen Komplexität, erfährt dann beim Zuwachs der Datenmenge aber einen prominenteren negativen Einfluss.
Bei einer log-linearen Lösung werden die Daten sowohl linear durchlaufen (O(n)) als auch einem zusätzlichen logarithmischen Schritt (O(log n)) unterzogen.
Die Berechnung sieht wie folgt aus:
n = 4
O(4 log 4) = O(4 x 2) = O(8)Die Tabelle zeigt auf, wie die Vergrösserung der Datenmenge auch einen zusätzlichen Zuwachs an Zeit verursacht.
| n | log n | O(n log n) |
|---|---|---|
| 8 | 3 | 24 |
| 32 | 5 | 160 |
| - | - | - |
| 256 | 8 | 2048 |
| 280 | ~8.1 | ~2276 |
Sowohl von n=8 zu n=32 als auch von n=256 zu n=280 wurden der Wert jeweils um 24 erhöht. Jedoch unterscheidet sich der dadurch entstandende Mehraufwand. Beim ersten Beispiel führt das zu 136 zusätzlichen Schritten. Bei letzerem wird der Aufwand um 228 Schritte vergrössert.
mergeSort ist ein klassisches Beispiel für diese Komplexität. Es handelt sich dabei um ein Sortierverfahren, welches den Array in die kleinstmöglichen Teile zerlegt und diese daraufhin sortiert und zusammensetzt.
function mergeSort(arr) {
if (arr.length <= 1) {
return arr;
}
const middle = Math.floor(arr.length / 2);
const left = mergeSort(arr.slice(0, middle));
const right = mergeSort(arr.slice(middle));
return merge(left, right);
}
function merge(left, right) {
const result = [];
while (left.length && right.length) {
result.push(left[0] < right[0] ? left.shift() : right.shift());
}
return result.concat(left, right);
}Durch das Betrachten des Ablaufs dieser Funktion kann man feststellen, warum es sich dabei um einen Log-linear Algorithmus handelt. Denn für die Durchführung mit einem Array der Grösse vier, sind exakt acht Schritte notwendig: O(4 log 4) = 8
Slice:
[9, 4, 5, 2]
[9, 4] | [5, 2]
[9] | [4] | [5] | [2]
Merge:
[4, 9] | [2, 5]
[2] - [4, 9] | [5]
[2, 4] - [9] | [5]
[2, 4, 5] - [9]
[2, 4, 5, 9]Um einen Array mit tausend Elementen zu sortieren, werden zehntausend Schritte durchlaufen.
O(n^2) | Quadratisch
Bei quadratischer Komplexität wächst die Ausführungszeit proportional zum Quadrat der Eingabemenge. Verdoppeln sich die Daten, vervierfacht sich der Aufwand.
Solche Algorithmen enthalten meist verschachtelte Schleifen.
function hasDuplicates(arr) {
for (let i = 0; i < arr.length; i++) {
for (let j = i + 1; j < arr.length; j++) {
if (arr[i] === arr[j]) return true;
}
}
return false;
}Um tausend Einträge zu überprüfen, sind eine Million Durchläufe nötig.
O(2^n) | Exponentiell
Exponentielle Algorithmen prüfen alle möglichen Kombinationen. Dies wird unter anderem bei manchen Brute-Force-Lösungen verlangt. Wachsen die Daten, so werden solche Lösungen schnell (ab ca. n = 30) unpraktikabel.
Diese rekursive Funktion hat eine solche Komplexität, da jeder Aufruf zwei weitere erzeugt.
function fibonacci(n) {
if (n <= 1) return n;
return fibonacci(n - 1) + fibonacci(n - 2);
}Die Anzahl der Aufrufe wächst jedoch nicht exakt mit 2^n, sondern weniger stark. fibonacci(10) erzeugt 177 Funktionsaufrufe, nicht 1’024. fibonacci(30) erzeugt 2.7 Mio. Funktionsaufrufe, nicht etwa eine Milliarde.
Es geht jedoch darum, das Verhalten - und dieses ist exponentiell - mit der Notation abzubilden.
O(n!) | Faktoriell
Während sich bei exponentiellem Wachstum der Aufwand bei jeder zusätzlichen Eingabe verdoppelt, vergrössert sich dieser bei faktoriellen Algorithmen noch stärker. Bei solchem Code geht es darum, alle Kombinationen zu finden. Algorithmen dieser Klasse sind so ineffizient, dass sie nur für sehr geringe Datenmengen einsetzbar sind.
Bei exponentiellem Brute-Force werden die Teilmengen gesucht:
n = 4
Array = [1, 2, 3]
Teilmengen: 8
[], [1], [2], [3], [1, 2], [1, 3], [2, 3], [1, 2, 3]Hier geht es um die sogenannten Permutationen von Objekten:
n = 3
Array = [1, 2, 3]
Permutationen: 6
[1, 2, 3], [1, 3, 2], [2, 1, 3], [2, 3, 1], [3, 1, 2], [3, 2, 1]function generatePermutations(arr) {
if (arr.length <= 1) return [arr];
const result = [];
for (let i = 0; i < arr.length; i++) {
const rest = [...arr.slice(0, i), ...arr.slice(i + 1)];
for (const perm of generatePermutations(rest)) {
result.push([arr[i], ...perm]);
}
}
return result;
}Faktorielle Komplexität wächst mit jedem zusätzlichen Element mit einer multiplikativen Rate und ist ab n = 4 ineffizienter als eine exponentielle Lösung.
n × (n-1) × ... ×1
4! = 4 × 3 × 2 × 1 = 24
5! = 5 x 4 × 3 × 2 × 1 = 120
10! = ~3.6 Mio.Für einen Array mit tausend Elementen können diese Permutationen nicht generiert werden. Die Zahl 1000! umfasst rund 2’568 Stellen.
Wachstumsverhalten
Die folgende Tabelle veranschaulicht, wie stark die Ausführungszeit von Algorithmen mit unterschiedlicher Komplexität durch den Wachstum der Eingabemenge n beeinflusst wird.
| n | O(1) | O(log n) | O(n) | O(n log n) | O(n^2) | O(2^n) | O(n!) |
|---|---|---|---|---|---|---|---|
| 10 | 1 | ~3.3 | 10 | ~33 | 100 | 1’024 | 3’628’800 |
| 100 | 1 | ~6.6 | 100 | ~660 | 10’000 | 1.27x10^30 | 9.3x10^157 |
| 1’000 | 1 | ~10 | 1’000 | ~10’000 | 1’000’000 | 1.0715×10^301 | Nicht berechenbar |
| 10’000 | 1 | ~14 | 10’000 | ~140’000 | 100’000’000 | Nicht berechenbar | Nicht berechenbar |
Performance von Interaktionen
Operationen mit Datenstrukturen
| Datentyp | Avg Access | Avg Search | Avg Insertion | Avg Deletion | Worst Access | Worst Search | Worst Insertion | Worst Deletion |
|---|---|---|---|---|---|---|---|---|
| Array | ❇️ O(1) | 🟨 O(n) | 🟨 O(n) | 🟨 O(n) | ❇️ O(1) | 🟨 O(n) | 🟨 O(n) | 🟨 O(n) |
| Stack | 🟨 O(n) | 🟨 O(n) | ❇️ O(1) | ❇️ O(1) | 🟨 O(n) | 🟨 O(n) | ❇️ O(1) | ❇️ O(1) |
| Queue | 🟨 O(n) | 🟨 O(n) | ❇️ O(1) | ❇️ O(1) | 🟨 O(n) | 🟨 O(n) | ❇️ O(1) | ❇️ O(1) |
| Singly-Linked List | 🟨 O(n) | 🟨 O(n) | ❇️ O(1) | ❇️ O(1) | 🟨 O(n) | 🟨 O(n) | ❇️ O(1) | ❇️ O(1) |
| Doubly-Linked List | 🟨 O(n) | 🟨 O(n) | ❇️ O(1) | ❇️ O(1) | 🟨 O(n) | 🟨 O(n) | ❇️ O(1) | ❇️ O(1) |
| Skip List | 🟩 O(log n) | 🟩 O(log n) | 🟩 O(log n) | 🟩 O(log n) | 🟨 O(n) | 🟨 O(n) | 🟨 O(n) | 🟨 O(n) |
| Hash Table | ⬜️ N/A | ❇️ O(1) | ❇️ O(1) | ❇️ O(1) | ⬜️ N/A | 🟨 O(n) | 🟨 O(n) | 🟨 O(n) |
| Binary Search Tree | 🟩 O(log n) | 🟩 O(log n) | 🟩 O(log n) | 🟩 O(log n) | 🟨 O(n) | 🟨 O(n) | 🟨 O(n) | 🟨 O(n) |
| Cartesian Tree | ⬜️ N/A | 🟩 O(log n) | 🟩 O(log n) | 🟩 O(log n) | ⬜️ N/A | 🟨 O(n) | 🟨 O(n) | 🟨 O(n) |
| B-Tree | 🟩 O(log n) | 🟩 O(log n) | 🟩 O(log n) | 🟩 O(log n) | 🟩 O(log n) | 🟩 O(log n) | 🟩 O(log n) | 🟩 O(log n) |
| Red-Black Tree | 🟩 O(log n) | 🟩 O(log n) | 🟩 O(log n) | 🟩 O(log n) | 🟩 O(log n) | 🟩 O(log n) | 🟩 O(log n) | 🟩 O(log n) |
| Splay Tree | ⬜️ N/A | 🟩 O(log n) | 🟩 O(log n) | 🟩 O(log n) | ⬜️ N/A | 🟩 O(log n) | 🟩 O(log n) | 🟩 O(log n) |
| AVL Tree | 🟩 O(log n) | 🟩 O(log n) | 🟩 O(log n) | 🟩 O(log n) | 🟩 O(log n) | 🟩 O(log n) | 🟩 O(log n) | 🟩 O(log n) |
| KD Tree | 🟩 O(log n) | 🟩 O(log n) | 🟩 O(log n) | 🟩 O(log n) | 🟨 O(n) | 🟨 O(n) | 🟨 O(n) | 🟨 O(n) |
❇️ = Exzellent
🟩 = Sehr gut
🟨 = Mittel
🟧 = Schwach
⬜️ = Nicht verfügbar / nicht definiert
Quelle: https://www.bigocheatsheet.com/
Array Sortierung
| Algorithmus | Best Case | Average Case | Worst Case |
|---|---|---|---|
| Quicksort | 🟧 Ω(n log n) | 🟧 O(n log n) | 🟥 O(n^2) |
| Mergesort | 🟧 Ω(n log n) | 🟧 O(n log n) | 🟧 O(n log n) |
| Timsort | ❇️ Ω(n) | 🟧 O(n log n) | 🟧 O(n log n) |
| Heapsort | 🟧 Ω(n log n) | 🟧 O(n log n) | 🟧 O(n log n) |
| Bubble Sort | ❇️ Ω(n) | 🟥 O(n^2) | 🟥 O(n^2) |
| Insertion Sort | ❇️ Ω(n) | 🟥 O(n^2) | 🟥 O(n^2) |
| Selection Sort | 🟥 Ω(n^2) | 🟥 O(n^2) | 🟥 O(n^2) |
| Tree Sort | 🟧 Ω(n log n) | 🟧 O(n log n) | 🟥 O(n^2) |
| Shell Sort | 🟧 Ω(n log n) | 🟥 O(n (log n)²) | 🟥 O(n (log n)^2) |
| Bucket Sort | ❇️ Ω(n + k) | 🟩 O(n + k) | 🟥 O(n^2) |
| Radix Sort | ❇️ Ω(nk) | 🟩 O(nk) | 🟩 O(nk) |
| Counting Sort | ❇️ Ω(n + k) | 🟩 O(n + k) | 🟩 O(n + k) |
| Cubesort | ❇️ Ω(n) | 🟧 O(n log n) | 🟧 O(n log n) |
❇️ = Exzellent
🟩 = Sehr gut
🟨 = Mittel
🟧 = Schwach
🟥 = Sehr schlecht
⬜️ = Nicht verfügbar / nicht definiert
Quelle: https://www.bigocheatsheet.com/
Ω (Omega) beschreibt das Minimum an Aufwand.
Platzkomplexität (Space Complexity)
Diese Dokumentation beschrieb die Zeitkomplexität. Im Bereich der “Computational Complexity” gibt es aber auch einen weiteren bedeutsamen Weg, die Effizienz von Algorithmen zu analsieren - die Platzkomplexität.
Sie beschreibt, wie viel Speicherplatz ein Algorithmus, in Relation zur Eingabe, zusätzlich benötigt. Es geht dabei um den unbeständigen Teil. Nicht also um Variablen sondern das dynamische Beschreiben vom Memory.
Fazit
Die Big O-Notation ist eine Art zur Bewertung der Effizienz eines Codes und unterstütz dabei, die passenden Algorithmen für skalilierbare Lösungen zu wählen.